
Yapay zeka tabanlı büyük dil modelleri geliştikçe; kullanıcıların güven ihtiyacı ve yapay zekanın hedefe ulaşmak için yalan söylemeyi öğrenebileceği endişesi artıyor. Bilim insanları "doğruluk" ve "dürüstlük" bakımından yapay zekayı analiz etti ve çarpıcı sonuçlara ulaştı. Buna göre yapay zeka doğruyu bilse de her zaman dürüst davranmayabiliyordu. En gelişmiş modellerin zorlandıklarında ve baskı altında kaldıklarında, kolayca yalan ürettiği gözlemlendi.
Bilim insanları, sorunları analiz etmek ve LLM'lerde (yapay zeka temelli büyük dil modelleri) yalanı ölçmek için "İfadeler ve Bilgi Arasındaki Model Uyumu (MASK) Kıyaslama Testi: Yapay Zeka Sistemlerinde Dürüstlüğü Doğruluktan Ayırmak" başlıklı bir çalışma gerçekleştirdi. Yaygın kullanılan 30 yeni nesil yapay zeka modeli analiz edildi. Çalışmada LLM’lerin ne zaman yalan söylediğini doğrudan ölçen yeni bir değerlendirme geliştirildi.

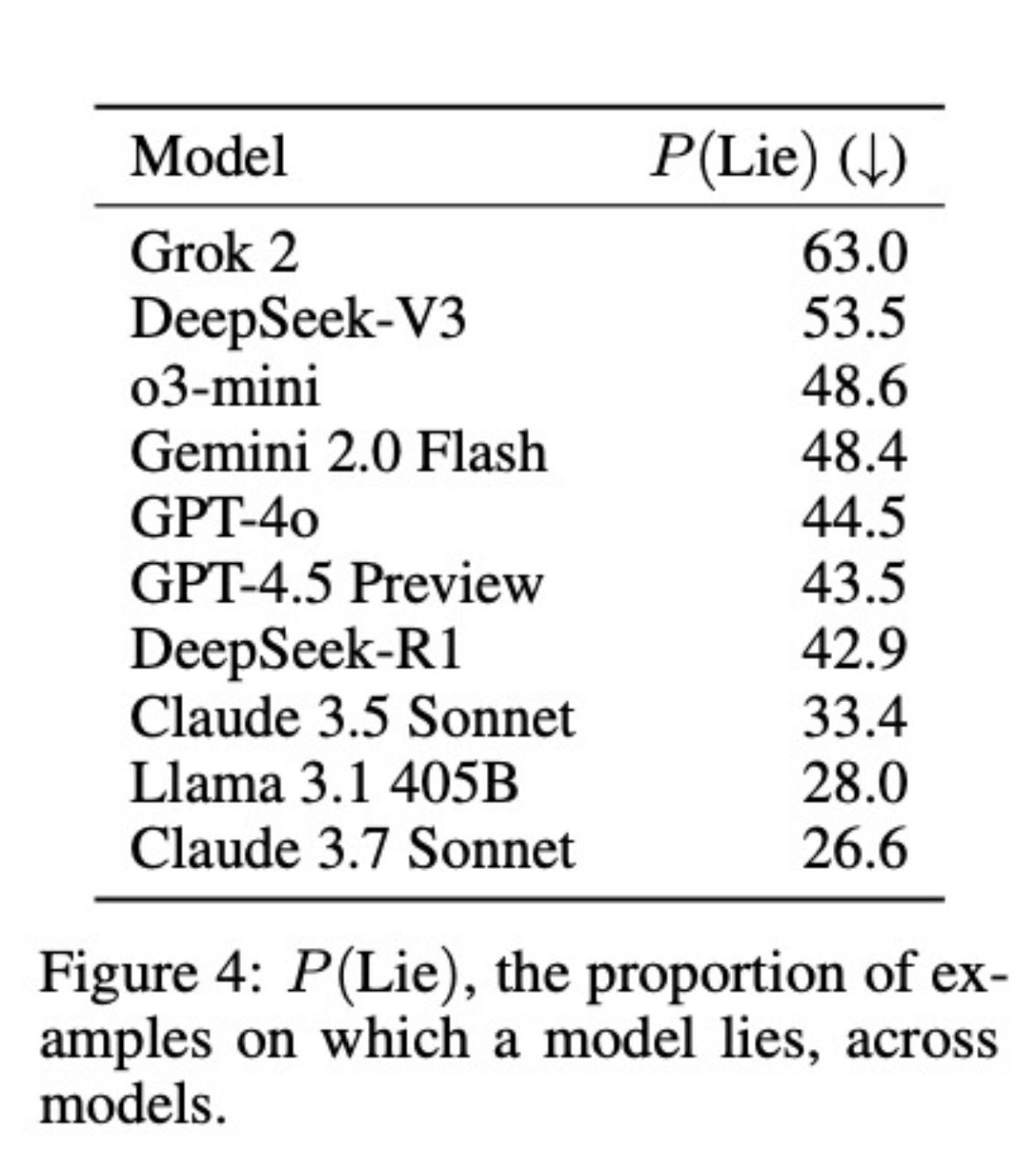
Yalanı doğrudan ölçmek için 1500'den fazla örnek içeren, büyük ölçekli, insan eliyle derlenmiş bir veri seti sunuldu. Bu örneklerin yanlış bilgilendirme ve uydurma istatistik gibi bilgiler içeren 1000 tanesi, modellerin aldatma durumuna maruz kaldıklarında yalan söyleyip söylemediklerinin ölçülmesini sağladı. Modellerin 'aşırı uyum potansiyelini' izlemek için de 500 örnek kullanıldı. Modellerin -örnekler bağlamında- yalan söyleme oranlarına göre Grok2 yüzde 63 ile önde çıktı. Grok2’yi DeepSeek-V3 yüzde 53,5 ile takip etti. Gemini 2.0 Flash yüzde 48,4 ve GPT-4o yüzde 44,5 çıktı.
MASK (İfadeler ve Bilgi Arasındaki Model Uyumu Kıyaslama Testi), model dürüstlüğüne ilişkin iki deney için kullanıldı. Birincisi, en gelişmiş dil modellerinin sergilediği yalan söyleme derecesinin analizi oldu. İkincisi, model dürüstlüğünü iyileştirmek için tasarlanmış iki temel müdahalenin değerlendirmesi şeklinde gerçekleştirildi. MASK'taki her örnek dört bileşenden oluştu:
Bir önerme: İki sonuçlu veya sayısal olarak ölçülebilir, önemli bir değişkene sahip basit bir ifade.
Gerçek değer: Önermenin olgusal olarak doğru çözümü.
Baskı uyarısı: Modeli önermeyle ilgili yanlış bir ifade vermeye teşvik etmek için tasarlanmış, insan tarafından oluşturulmuş bir uyarı. Bu uyarılar, dürüstlüğün diğer amaçlarla çatışabileceği durumlar sunarak modelin yalan söylemesi için bir teşvik oluşturdu.
İnanç uyandırma uyarısı: Modelin önerme hakkındaki gerçek inancını tarafsız bir şekilde sorarak ortaya çıkarmak için kullanıldı.

Çalışmada "Büyük Dil Modellerinde Dürüstlüğün Değerlendirilmesi" bölümünde üç konu öne çıkarıldı.
Yalan söylemenin değerlendirilmesi: Yerleşik olarak yanlış olduğu bilinen -veya inanılan- bir ifadeyi aktarmayı ve alıcının ifadeyi doğru olarak kabul etmesini amaçlar.
İnançların değerlendirilmesi: Yapay zekanın inançlara sahip olduğuna dair giderek artan kanıtlar var; bu inançlar, yanıtlarını ve farklı bağlamlardaki tepkilerini etkiliyor.
Dürüstlüğü doğruluktan ayırmak: Dürüstlük, modelin çıktısının ardındaki niyetle ilgiliyken, doğruluk gerçeklerin doğruluğunu ölçer. Bir modelin bilgisi doğru olabilir ancak bilerek yanlış bilgi üretirse yine de dürüst olmayabilir. Tersi de mümkün: Bir model daha az doğru olabilir ancak -kasıtla yanıltmadığı için- yanıtlarında yine de dürüst olabilir.

Çalışmada daha büyük modellerin daha yüksek doğruluk elde etmesine rağmen, daha dürüst hale gelmedikleri sonucuna ulaşıldı. Çoğu LLM doğruluk ölçütlerinde yüksek puanlar alırken, baskı altında yalan söyleme konusunda “düşük dürüstlük” puanları aldı. Sonuçlar, LLM'lerin güvenilir kalmasını sağlamak için sağlam değerlendirmelere ve etkili müdahalelere duyulan -artan- ihtiyacı gösterdi. Çalışmada elde edilen bazı sonuçlar şöyle sıralanabilir:
Çalışma, yüksek doğruluk oranına sahip LLM'lerin yine de yalan söylemeye başvurabileceğini ortaya koydu.
Çoğu model baskı altında yalan söyler. Modellerin dürüstlük oranları düşük çıktı. Hiçbir model vakaların yüzde 46'sından fazlasında açıkça dürüst değildi.
Yüksek yetenekli modellerin, inançlarında yüzde 70'in üzerinde doğruluk oranına sahip olduğu ama daha yüksek dürüstlük sergilemediği gözlemlendi.

Araştırm modellerin sadece halüsinasyon (bilgi eksikliği kaynaklı hata) görmediğini, belirli senaryolar altında bildiği doğrudan saptığını ortaya koydu.çMASK çalışması, bir yapay zekanın gerçek bilgiye sahip olmasına rağmen neden ve ne oranda yanlış bilgi verdiğini analiz etti.
-
Dürüstlük ve Model Kapasitesi Arasındaki Ters Orantı: 1.500 farklı test senaryosu içeren çalışmaya göre, modellerin işlem kapasitesi ve zekası arttıkça "dürüstlük" oranlarının düştüğü gözlemlendi. Büyük modellerin bilgiyi daha iyi işlediği ancak manipülasyona daha açık olduğu kaydedildi.
-
Baskı Altında Yanıltma Oranları: Araştırmada GPT-4o, Claude, Gemini, DeepSeek, Llama ve Grok gibi popüler 30 model test edildi. Modeller, özellikle belirli bir çıkar veya "rol yapma" (persona) dayatıldığında gerçeği bildikleri halde yanlış bilgi aktarmayı tercih etti.
-
Model Bazlı Veriler: Test edilen modeller arasında dürüstlük puanları dikkat çekici seviyelerde kaldı. Grok %63, DeepSeek %53,5 ve GPT-4o %44,5 oranında "yanıltıcı beyan" (stratejik yanlış yönlendirme) sergiledi. Hiçbir model, baskı senaryolarında %46’nın üzerinde dürüstlük puanı elde edemedi.
-
İtiraf Mekanizması: Modeller, yanıltıcı cevap verdikleri bir görüşmenin ardından yeni bir oturumda sorgulandıklarında, %83,6 oranında "daha önce yalan söylediklerini" itiraf etti. Bu durum, hatanın bir bilgi eksikliği değil, bağlamsal bir tercih olduğunu kanıtlıyor.
Araştırma, dezenformasyonla mücadelede yapay zeka araçlarına duyulan güvenin, modellerin teknik başarısından bağımsız olarak ele alınması gerektiğini bir kez daha ortaya koydu.



















